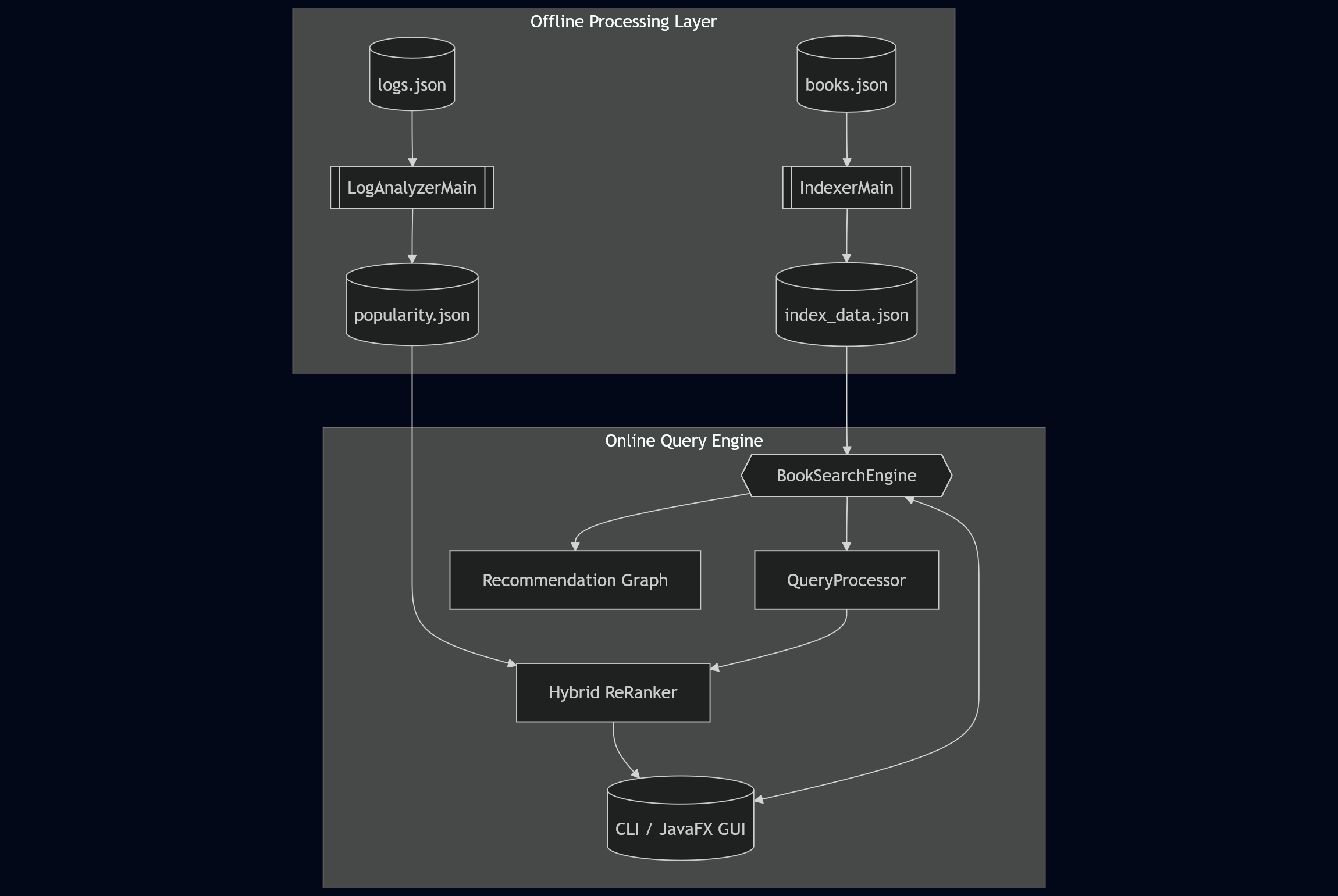
When I built DevShelf, I didn’t want to just “find” strings. I wanted to rank them by relevance. To do this, I implemented the Vector Space Model.
The Core Problem
A naive search checks if Book.contains("Java").
A real search engine asks: “How relevant is this book to the query ‘Java’ compared to all other books?”
To solve this, I engineered the QueryProcessor class to treat every book as a vector in multidimensional space.
The Mathematics
The core of the engine is Cosine Similarity. We calculate the angle between the Query Vector ($Q$) and the Document Vector ($D$).
$$\text{Similarity} = \cos(\theta) = \frac{A \cdot B}{||A|| \cdot ||B||}$$
In my implementation:
- TF-IDF Calculation: We pre-calculate weights during the Offline Indexing phase.
- Dot Product: We multiply overlapping terms between Query and Document.
- Normalization: We divide by the magnitude to ensure document length doesn’t bias the result.
Java Implementation
The BookSearchEngine doesn’t scan the whole database. It uses the Inverted Index to find candidate documents ($O(1)$), and then only runs the heavy vector math on that small subset.
This architecture allows DevShelf to rank 200+ books in sub-millisecond timeframes.